简介
Compute Unified Device Architecture (CUDA) 是由 NVIDIA 开发的并行计算平台和编程模型。它使开发人员能够使用 CUDA-C 编写程序,利用 CUDA 架构的 NVIDIA GPU 加速应用程序的运行。简单来说,就是利用 GPU 的并行计算能力来加速计算。
本文主要记录一些笔者在学习 CUDA 编程过程中的杂项记录。
需要注意,对于 GPU 编程而言,一般通过 host 和 device 区分 CPU 和 GPU,即后文若有提到,则 host 指 CPU,device 指 GPU。
CUDA GPU 软件结构
引用一张并不如何美观的图片来解释 CUDA 编程结构:由三部分组成,分别是 Grid、Block 和 Thread。中文翻译是网格、块和线程——不过作为指代 GPU 结构的名词,为保证不和其他概念如 OS 中的线程混淆,可能还是用英文表达更合适。
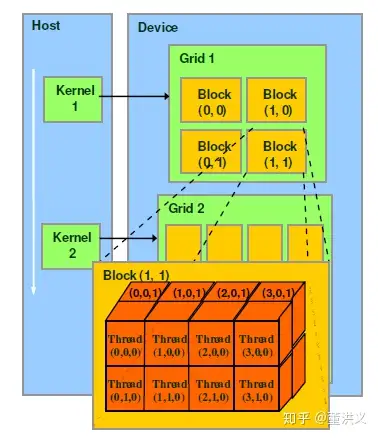
调用任何的 CUDA 核函数(即运行在 GPU 上的函数)都需要指定要在“多少 Block,多少 Thread”上运行,调用格式如下:
1 | dim3 gridDim(2, 2, 1); // 一个 Grid 包含 2x2 个 Block |
注意到这里传入了两个 dim3 类型的变量,分别指定了 Grid 和 Block 的大小。这里我们指定大小可以用一维、二维或三维的方式,比如 dim3(2, 2, 1) 和 dim3(4, 4, 1) 可以等价地写成 dim3(2, 2) 和 dim3(4, 4)。这里的 <<<>>> 语法是 CUDA 中的特有的调用核函数的语法,用来指定 Grid 和 Block 的大小。
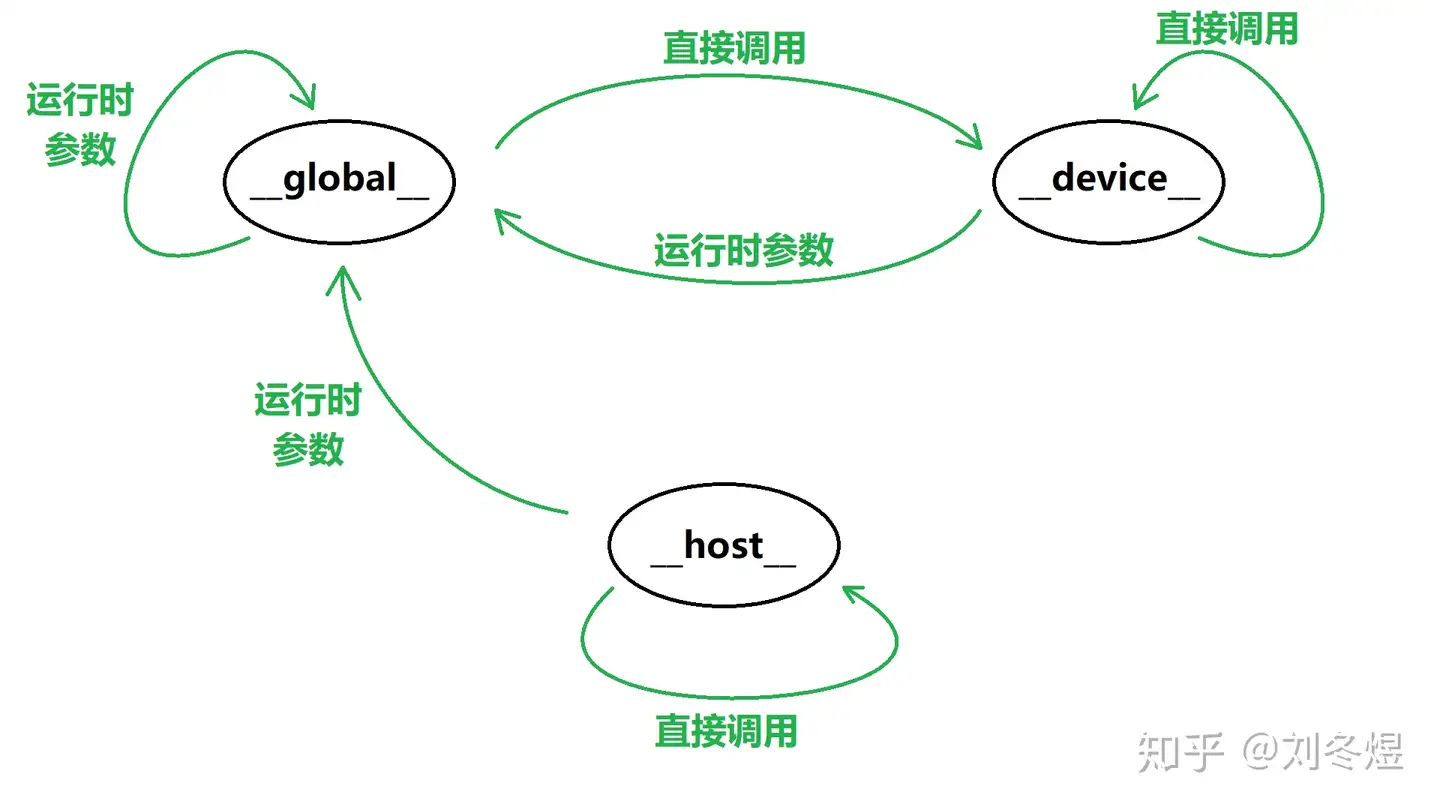
那么,什么是核函数呢?简单来说,就是运行在 GPU 上的函数。为了区分代码中哪些函数是运行在 CPU 上,哪些是运行在 GPU 上,CUDA 中使用关键字来修饰运行在 GPU 上的函数,包括 __global__、__device__ 和 __host__。其中 __host__ 就是运行在 CPU 上的函数(如果函数声明不额外添加关键字,也会被默认当成 __host__ 函数),显然,能调用 __host__ 函数的只有同类型的 __host__ 函数。__device__ 和 __global__ 是运行在 GPU 上的函数,其中 __device__ 函数只能被 GPU 上的两种函数调用,而 __global__ 函数可以被 __host__ 函数通过传递运行时参数的方式调用。这里的 __global__ 函数就是我们通常所说的核函数。
此外,对于 sm_50 以上的计算能力的 GPU,CUDA 支持 __device__ 函数的递归(在此之前都是直接内联)。而 __device__ 和 __global__ 函数都可以继续通过传递运行时参数的方式调用 __global__ 函数,实现某种多级并行。综合来说,如下图所示:
CUDA GPU 硬件架构
一个 GPU 由多个 SM(Streaming Multiprocessor)组成,每个 SM 包含多个 SP(Streaming Processor)。形象化解释的话,SM 是一个工人小组,SP 则是单个工人。具体的指令和任务都是一个 SP 一次执行一条,也可以将 SP 理解为一个丐版 CPU 核心。一个 SM 有一定数量的寄存器和 shared 内存,前者和 CPU 的寄存器相同,后者相当于仅供 SM 内部读写的高速内存(相对应的还有更慢的 global 内存,也是大家通常说的显存,其对所有 SM 都可见)。如下图为一个 SM 的基本组成:
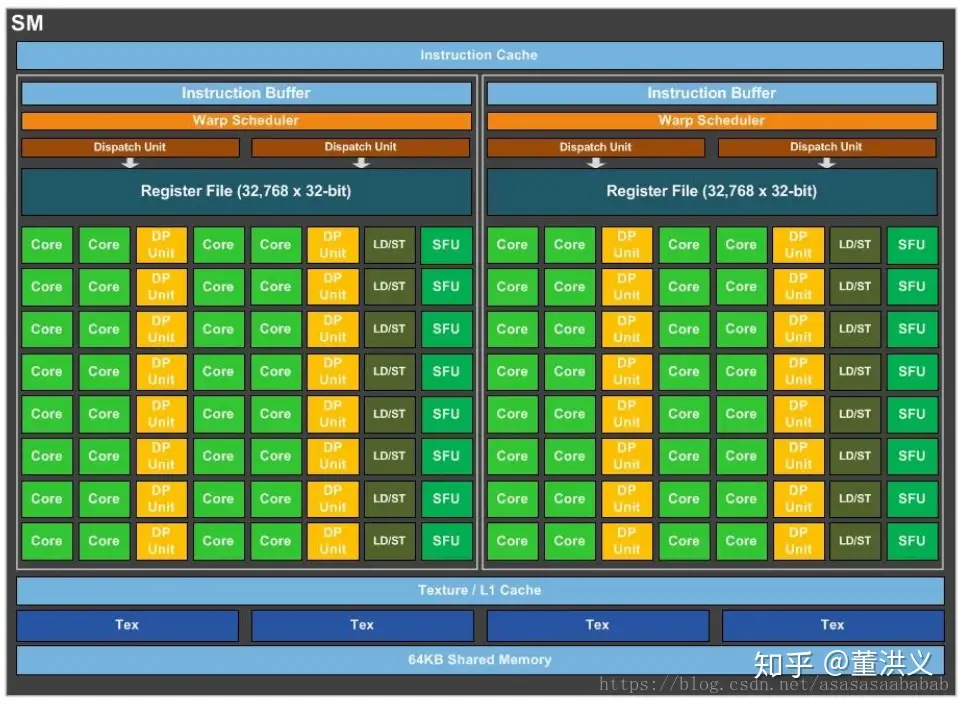
一个 SP 可以执行一个 thread,而若干个(目前是 32 个,不排除以后 NVIDIA 会改) threads 组成一个 warp,由 SM 的 warp scheduler 负责调度。一个 SM 同时可以执行多个 warp,是调度和运行的基本单元(有点类似于进程)。
对于一个 warp 中的 32 个 threads(我们目前认为他 32 个),它们的执行是 SIMT(Single Instruction Multiple Thread)的,即同一个指令同时作用于这 32 个 threads,但是每个 thread 的数据不同。对于一些控制流语句如 if,else 等,不同的 threads 如果需要进入不同的分支,那么 warp 只能够走其中一条分支,将剩余的 threads 暂时阻塞,这就叫 warp divergence,十分影响性能,如下图:
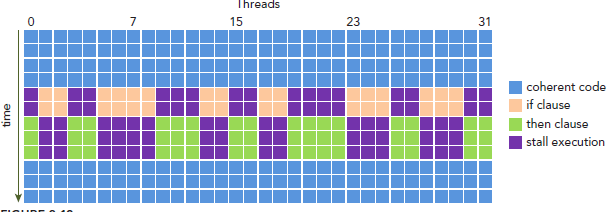
为了减少这种情况发生,提升性能,一种方法是保证同一个 warp 内的 threads 走同一个方向。比如一个分支决定条件是 tid % 2 == 0,那么可以改成 (tid >> 5) & 1 == 0,这样就保证了同一个 warp 内的 threads 都走同一个分支。不过由于 NVIDIA 的工程师也很聪明,很多时候 nvcc 也会自动帮我们完成类似的优化。
对于一个 warp 而言,其上下文包括三个部分:PC(指令计数器),寄存器和 shared 内存。其中 PC 含义和 CPU 中的 PC 含义相同。需要注意的是,对于 warp 而言,上下文切换是没有消耗的,因为所有的 warp 的寄存器和 shared 内存都同时存在于 SM 中,因此切换 warp 的上下文只需要改变 PC 即可,不需要保存和恢复寄存器和 shared 内存。
在一个 block 中有多个 warp,如果硬件资源满足要求,就会将 warp 送入 SM 中执行。由于 threads 的调度以 warp 为单位,因此它们不一定是同步的。如果需要对 threads 进行同步,可以使用 __syncthreads() 函数,它会阻塞当前 warp 中的 threads,直到所有 threads 都到达这个函数,然后再继续执行。需要注意的是,这个函数只能在同一个 block 中的 threads 之间同步,不同 block 之间的 threads 无法通过这个函数同步。
CUDA 内存管理
在 CUDA 编程中,我们需要显式管理各个变量存储位置是主存还是显存。首先,声明在 __host__ 函数中的变量只能存储在主存中。然后对于不添加关键字的全局变量,同样存储在主存中。如果想将全局变量存储在 GPU 上,需要加上 __device__ 或 __constant__ 关键字。两者均存储在 GPU 的高速内存中,但后者作为常量,可以被放在高速缓存中,提升 GPU 对其的读取效率。需要注意的是,__constant__ 并不是真正的常量,它的值可以被 host 修改,只是对于 GPU 而言,它是只读的。对这两个关键字声明的全局变量,需要通过 cudaMemcpyToSymbol() 和 cudaMemcpyFromSymbol() 函数来在 host 和 device 之间传递数据。此外,CUDA 还提供了 __shared__ 关键字,用来声明存储在 GPU 的共享内存中的变量,这个关键字只能在 __global__ 或 __device__ 函数中使用,用来在同一个 Block 中的 Thread 之间共享数据,速度快于前面两种内存,但容量很小。需要注意的是,对于在核函数中声明的,未标注 __device__ 的变量,它们一般会被存储在寄存器中。
同时,也可以通过 cudaMalloc() 和 cudaFree() 函数来在 host 和 device 之间传递数据,这两个函数分别用来在 device 上分配内存和释放内存,对于这种方式申请的显存,使用普通的指针记录其地址即可。此外,还有 cudaMemcpy() 函数用来在 host 和 device 之间传递数据,它的参数比较多,可以指定传递的数据大小、传递的方向等。这些函数的返回值均为 cudaError_t 类型,可以通过 cudaGetErrorString() 函数来获取错误信息,一般通过 assert( cudaSuccess == err ) 来检查是否出错。这几个函数均为 host 函数,即只能在 __host__ 函数中调用。对于在核函数中类似的申请需求,直接调用 malloc() 和 free() 即可,这两个函数会在 device 上分配内存,但是需要注意,这两个函数的返回值是 void* 类型,需要强制转换为对应的类型。
对于 device 的内存传递,有的代码会采用将指针转
float4类型的方式来传递。这个类型代表了 4 个float类型的数据放在一起,因此通过reintepret_cast<float4*>(ptr)来转换指针再进行数据传递的话,就可以通过可能更快的向量化指令来进行数据传递。
Bank Conflict
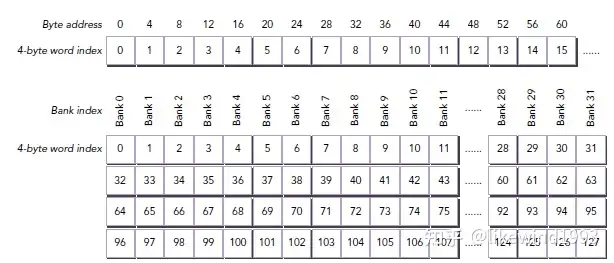
首先,在 CUDA 中,shared 内存能够被一个 warp 中的所有线程访问。其中 shared 内存以 bank 的形式分层组织。具体如下图所示。每个 warp 有 32 个 threads,因此 shared 内存也被分为了 32 个 bank。一个 bank 一层的大小为 4Byte = 32bit。而实际的数据先连续的分成 32 * 4Byte 大小的层,每层再划分给 32 个 bank。因此如果每个 thread 每次读写 shared 内存能够恰好读取这 32 个 bank,那么将能够做到同时读取。
Bank confict 指的就是当多个 thread 同时读写同一个 bank 的情况。如下图左侧无 bank conflict,中间每两个 thread 读写同一个 bank 则有 bank conflict,右边虽然映射比较乱但是没有 bank conflict。
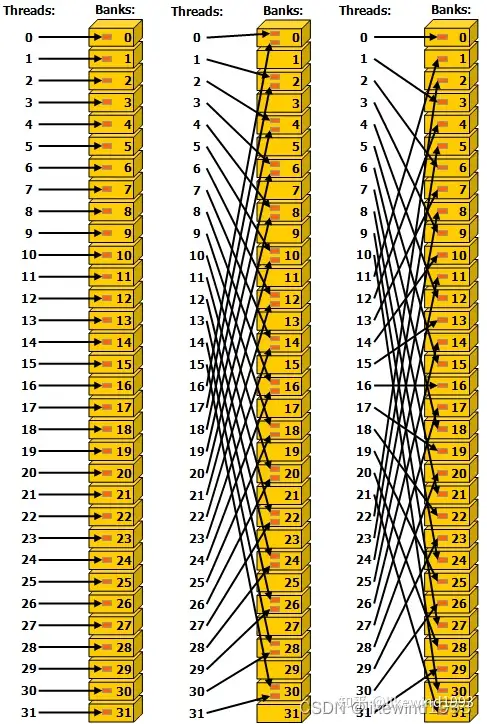
实际实现中,对于 bank conflict 即多个 thread 读写同一个 bank 的情况,warp 会将这些操作串行化从而导致性能降低。具体来说,当多个 thread 同时读一个 bank 时,会变成顺序读取(新版本中变为一个 thread 读取然后 broadcast 到其余 thread)。而当多个 thread 同时写一个 bank 时,会随机一个 thread 成功。
因此在进行核函数编写时,需要尽量保证对 shared 内存的访问是连续映射的,或保证各个 thread 访问的 shared 内存地址模 32 互相不同余。